Attend and Guide (AG-Net): A Keypoints-driven Attention-based Deep Network for Image Recognition
Asish Bera, Zachary Wharton, Yonghuai Liu, Nik Bessis, and Ardhendu Behera
Department of Computer Science, Edge Hill University, United Kingdom
Abstract
Deep Convolutional Neural Networks (CNNs) for recognizing images with distinctive classes have shown great success, but their performance in discriminating fine-grained changes is not at the same level. We address this by proposing an end-to-end CNN model, which learns meaningful features linking fine-grained changes using our novel attention mechanism. It captures the spatial structures in images by identifying semantic regions (SRs) and their spatial distributions, and is proved to be the key to modeling subtle changes in images. We automatically identify these SRs by grouping the detected keypoints in a given image. The “usefulness” of these SRs for image recognition is measured using our innovative attentional mechanism focusing on parts of the image that are most relevant to a given task. This framework applies to traditional and fine-grained image recognition tasks and does not require manually annotated regions (e.g. bounding-box of body parts, objects, etc.) for learning and prediction. Moreover, the proposed keypoints-driven attention mechanism can be easily integrated into the existing CNN models. The framework is evaluated on six diverse benchmark datasets. The model outperforms the state-of-the-art approaches by a considerable margin using Distracted Driver V1 (Acc: 3.39%), Distracted Driver V2 (Acc: 6.58%), Stanford-40 Actions (mAP: 2.15%), People Playing Musical Instruments (mAP: 16.05%), Food-101 (Acc: 6.30%) and Caltech-256 (Acc: 2.59%) datasets.
Attend and Guide (AG-Net)
A novel method for generating sematic regions by loacalizing salient keypoints and grouping them using the Gaussian Mixture Model (GMM). These semantic regions are aimed to attain local to global contextual information involving smaller patches to larger patches to the whole image. Our AG-Net is trained in an end-to-end fashion to recognize images from these semantic regions be learning to attend each region by its importance towards classification decision using a novel attention module.
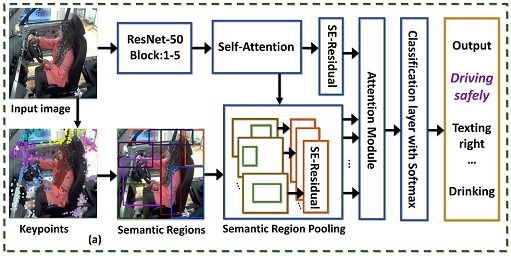
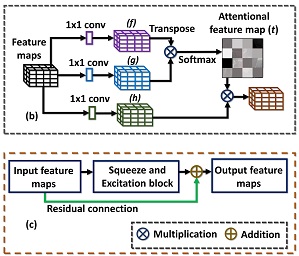
Proposed keypoint-driven attention-based visual recognition model (AG-Net): (a) Used for recognizing different fine-grained activities in still images (e.g., the input image is classified as driving safely activity). (b) Detailed Self-Attention block adapted from SAGAN. (c) The proposed residual connection to the Squeeze-and-Excitation block is used for pooling features from semantic regions.

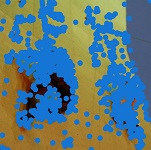
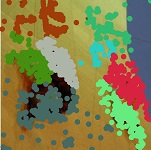




Climbing action from Stanford-40 dataset: Original image → detected SIFT keypoints → clustered keypoints → bounding boxes enclosing semantic regions. Drinking image from AUC-V2 datasetr: Original image → detected two primary semantic regions (red and green) → secondary semantic regions (blue) along with the primary ones.








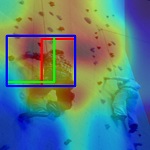





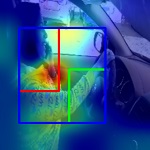

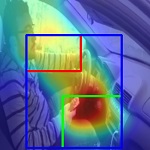
Visualization of class activation maps using the Grad-CAM. The top row describes three distinctive actions from: (a) Stanford-40, (b) PPMI-24, and (c) AUC-V2. The bottom row depicts the corresponding activation map of salient regions on which we have overlaid only three semantic regions for clarity. It contains two primary semantic regions (enclosed with red and green bounding-boxes) along with a secondary region (enclosed with blue bounding-box) which is derived from those two primaries.
Paper and Supplementary Information
Extended version of the accepted paper in Edge Hill University Repository.
Bibtex
@article{bera2021attend,
title={Attend and Guide (AG-Net): A Keypoints-Driven Attention-Based Deep Network for Image Recognition},
author={Bera, Asish and Wharton, Zachary and Liu, Yonghuai and Bessis, Nik and Behera, Ardhendu},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={3691--3704},
year={2021},
publisher={IEEE}
}
Acknowledgements
This research was supported by the UKIERI (CHARM) under grant DST UKIERI-2018-19-10. The GPU is kindly donated by the NVIDIA Corporation.